The great caffeine conundrum
More and more of us are routinely logging data about our health and wellbeing. How can we use that data to inform and adapt our behaviour? How can we avoid over-interpreting what we experience? Here’s a real-world example.
There are lots of little changes that, we are told, could improve our health, wealth, and happiness in small, incremental ways. The problem is, in part, knowing which ones will work for us, which ones work for other people, and which ones are utter nonsense.
We can get a good head start on assessing what is likely (or not likely) to work using the same sort of tools that are used for evidence-based medicine. In particular, organisations like the Cochrane Collaboration produce reviews of evidence that can tell us about the relative efficacy of different interventions, many of which are non-pharmaceutical. There are even databases. For example, the Database of Abstracts of Reviews of Effectiveness (DARE) at the University of York is pretty cool, although its funding is due to end in January 2015.
We don’t need to rely on other peoples’ reviews, though. Looking at evidence can be fairly straightforward and there’s no reason why we can’t do most of the searching ourselves. A bit of time spent searching the US National Library of Medicine databases can be very informative.
Unfortunately, even the best review cannot always tell us what will work for us. There are a number of very good reasons for this:
- Aggregate effects – Systematic reviews and meta-analyses are generally based around average effects in the population. That means that they are useful for telling us what to do for a group of people, but they only give us limited information about individual responses
- Selective reporting – People spend a lot of time and effort promoting their worldview. Even in the scientific literature, a worrying number of publications appear to fit with the authors’ preconceived ideas. In other words, people often select the evidence that fits their ideas and ignore other data. I would include in here much of the misuse of statistics
- Unclear reporting – A lot of material is written in a way that makes it very difficult to understand. We’re all guilty of this to some extent, but technical publications really do take the biscuit. Systematic reviews, which should be nice and clear, are now so obsessed with demonstrating objectivity that they can often bury the relevant material deep inside the text about their methods
With formal medical treatments of existing illnesses, the gap between evidence-based medicine and the effects we expect in an individual should be filled by clinical expertise. An important role of the clinician is to take their expertise about the way humans work and interpret the evidence to make an informed guess about what will work for an individual patient.
For other types of intervention, it can be difficult to find someone to bridge the gap.
In reality, when the risks of an intervention are apparently very small and when our professional guides are uncertain, we may just experiment on ourselves. The problem here is that we know what to expect and often second-guess the outcome of our experiment.
What about the caffeine?
This brings us neatly to my brother and coffee. My brother (usually) drinks loads of it, and he decided to take a break and see what would happen. In fact, he decided to steer clear of all caffeine for a bit and see what happened.
This is important. He is not normal. He drinks more coffee than most people, so stopping caffeine consumption should have a greater effect than in most people.
Stage 1: Why are you doing it?
Stopping caffeine consumption could have lots of effects on my brother. It could affect his digestion, give him withdrawal symptoms (e.g. headaches, lethargy), impair his social life, or influence his home life by making him irritable. In an ideal world, I would have listed out all these possible effects and planned some data collection activities to look at them.
But I found out late in the day, so I could only use the data that he collected routinely or could remember. That’s always a challenge, so the best thing is to concentrate on the basics: Why are you doing it?
In my brother’s case, he was cutting out caffeine for some weird body-composition experiment that I didn’t have access to. However, he was also interested to see if it improved his sleep. That gives us a broad initial question:
Does removing caffeine from his diet improve my brother’s sleep?
He told me that his sleep was better. We’ll return to this later.
Stage 2: Get some data
There are lots of intricacies to data collection. There are problems relying on memories of events, there are wish-fulfilment biases, measurement errors, silly psychometric mistakes, and scales that affect the thing they’re trying to measure. It’s a minefield.
Don’t worry about that. You should worry about it if you’re choosing what treatments to provide to terminally ill patients. If you’re making a personal decision about whether to drink coffee, who cares? You need to be confident in the data yourself, and you should be critical (as we’ll see in a moment), but don’t be too daft. You can always change your mind.
My brother had an advantage. He’d been routinely collecting information for some time using a bit of wearable tech called a Jawbone UP. That’s not an endorsement, it’s just a fact. The UP records sleep quality.
That last statement is, of course, nonsense. A measure of sleep quality would probably be a questionnaire of some sort. The precise claim on the UP website is:
UP uses Actigraphy to track your sleep, monitoring your micro movements to determine whether you are awake, in light sleep, or in deep sleep
This translates as an accelerometer that can measure movement, combined with some filters to allow an assessment of whether sleep is ‘light’ or ‘deep’. There’s also an overall ‘sleep quality’ measure that is, presumably, calculated by little pixies in the wristband with a detailed knowledge of human physiology. Or not.
There’s a break down of the data available on their forums.
In summary, my guess is ‘light sleep’ means a bit of stirring and ‘deep sleep’ means immobility of near comatose proportions. There’s also a column of data for ‘REM sleep’, but that just contains zeroes for some reason. A lab-controlled environment with professional measurement it ain’t. But it’s probably better than asking him about his sleep a month later.
Stage 3: Look at the data
Always look at data. That’s what it’s there for. Here’s the data:
[chartboot version= ‘3.0’ code= ‘2CE6’ border= ‘1’ width= ‘800’ height= ‘400’ attribution= ‘1’ jsondesc= ‘{“containerId”:”visualization2CE6″,”dataTable”:{“cols”:xxx00xxx{“id”:””,”label”:”Date”,”pattern”:””,”type”:”string”,”p”:{}},{“id”:””,”label”:”Deep sleep duration”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Light sleep duration”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Night waking duration”,”pattern”:””,”type”:”number”}xxx01xxx,”rows”:xxx00xxx{“c”:xxx00xxx{“v”:”01/01/2014″,”f”:null},{“v”:245.0833333333,”f”:null},{“v”:156,”f”:null},{“v”:67.9333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/01/2014″,”f”:null},{“v”:197.0166666667,”f”:null},{“v”:335.9166666667,”f”:null},{“v”:37.75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/01/2014″,”f”:null},{“v”:217,”f”:null},{“v”:358,”f”:null},{“v”:25.0166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/01/2014″,”f”:null},{“v”:249.0166666667,”f”:null},{“v”:228,”f”:null},{“v”:43.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/01/2014″,”f”:null},{“v”:168,”f”:null},{“v”:179,”f”:null},{“v”:32.8833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/01/2014″,”f”:null},{“v”:220,”f”:null},{“v”:322,”f”:null},{“v”:75.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/01/2014″,”f”:null},{“v”:265.0166666667,”f”:null},{“v”:251.6833333333,”f”:null},{“v”:54.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/01/2014″,”f”:null},{“v”:307.9666666667,”f”:null},{“v”:228,”f”:null},{“v”:58.0833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/01/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/01/2014″,”f”:null},{“v”:142.0166666667,”f”:null},{“v”:247.6666666667,”f”:null},{“v”:43.4166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/01/2014″,”f”:null},{“v”:197.5833333333,”f”:null},{“v”:177.5666666667,”f”:null},{“v”:83.8333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/01/2014″,”f”:null},{“v”:255,”f”:null},{“v”:231.5833333333,”f”:null},{“v”:39.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/01/2014″,”f”:null},{“v”:207.0166666667,”f”:null},{“v”:241.9833333333,”f”:null},{“v”:44.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/01/2014″,”f”:null},{“v”:168,”f”:null},{“v”:226,”f”:null},{“v”:22.15,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/01/2014″,”f”:null},{“v”:222,”f”:null},{“v”:194.6,”f”:null},{“v”:106.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/01/2014″,”f”:null},{“v”:260.0833333333,”f”:null},{“v”:179,”f”:null},{“v”:51.2666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/01/2014″,”f”:null},{“v”:139,”f”:null},{“v”:273,”f”:null},{“v”:41.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/01/2014″,”f”:null},{“v”:248.5,”f”:null},{“v”:192,”f”:null},{“v”:72.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/01/2014″,”f”:null},{“v”:236,”f”:null},{“v”:215,”f”:null},{“v”:33.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/01/2014″,”f”:null},{“v”:141,”f”:null},{“v”:304.7,”f”:null},{“v”:54.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/01/2014″,”f”:null},{“v”:140,”f”:null},{“v”:223,”f”:null},{“v”:68.4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/01/2014″,”f”:null},{“v”:288.1333333333,”f”:null},{“v”:211.1,”f”:null},{“v”:54.9333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/01/2014″,”f”:null},{“v”:144.0333333333,”f”:null},{“v”:231.5833333333,”f”:null},{“v”:25.5333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/01/2014″,”f”:null},{“v”:163.7,”f”:null},{“v”:281.1666666667,”f”:null},{“v”:51.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/01/2014″,”f”:null},{“v”:192.0166666667,”f”:null},{“v”:227.9833333333,”f”:null},{“v”:35.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/01/2014″,”f”:null},{“v”:229,”f”:null},{“v”:239.3833333333,”f”:null},{“v”:31.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/02/2014″,”f”:null},{“v”:216.25,”f”:null},{“v”:195.9833333333,”f”:null},{“v”:38.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/02/2014″,”f”:null},{“v”:221,”f”:null},{“v”:210,”f”:null},{“v”:26.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/02/2014″,”f”:null},{“v”:204.9833333333,”f”:null},{“v”:241,”f”:null},{“v”:44.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/02/2014″,”f”:null},{“v”:164.0166666667,”f”:null},{“v”:259.55,”f”:null},{“v”:26.8333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/02/2014″,”f”:null},{“v”:175.55,”f”:null},{“v”:264.9833333333,”f”:null},{“v”:25.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/02/2014″,”f”:null},{“v”:188,”f”:null},{“v”:213,”f”:null},{“v”:68.3666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/02/2014″,”f”:null},{“v”:160.9833333333,”f”:null},{“v”:294.1166666667,”f”:null},{“v”:35.7333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/02/2014″,”f”:null},{“v”:252,”f”:null},{“v”:224.4166666667,”f”:null},{“v”:84.5666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/02/2014″,”f”:null},{“v”:178.0166666667,”f”:null},{“v”:211.9833333333,”f”:null},{“v”:33.0666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/02/2014″,”f”:null},{“v”:223.0166666667,”f”:null},{“v”:187.7666666667,”f”:null},{“v”:31.05,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/02/2014″,”f”:null},{“v”:207.0166666667,”f”:null},{“v”:240.9833333333,”f”:null},{“v”:33.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/02/2014″,”f”:null},{“v”:176.0166666667,”f”:null},{“v”:220.55,”f”:null},{“v”:70.15,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/02/2014″,”f”:null},{“v”:254.0166666667,”f”:null},{“v”:114.1333333333,”f”:null},{“v”:76.6,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/02/2014″,”f”:null},{“v”:212,”f”:null},{“v”:176,”f”:null},{“v”:46.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/02/2014″,”f”:null},{“v”:173.1833333333,”f”:null},{“v”:291,”f”:null},{“v”:28.6,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/02/2014″,”f”:null},{“v”:160,”f”:null},{“v”:235,”f”:null},{“v”:40.75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/02/2014″,”f”:null},{“v”:198,”f”:null},{“v”:261,”f”:null},{“v”:30.05,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/02/2014″,”f”:null},{“v”:234.0666666667,”f”:null},{“v”:195.9666666667,”f”:null},{“v”:31.5833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/02/2014″,”f”:null},{“v”:139,”f”:null},{“v”:258.05,”f”:null},{“v”:46.7833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/02/2014″,”f”:null},{“v”:146,”f”:null},{“v”:254.0166666667,”f”:null},{“v”:20.4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/02/2014″,”f”:null},{“v”:165.0166666667,”f”:null},{“v”:263.9,”f”:null},{“v”:50.7166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/02/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/02/2014″,”f”:null},{“v”:176.0166666667,”f”:null},{“v”:240.9833333333,”f”:null},{“v”:85.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/02/2014″,”f”:null},{“v”:265.5666666667,”f”:null},{“v”:170.25,”f”:null},{“v”:48.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/02/2014″,”f”:null},{“v”:152.5333333333,”f”:null},{“v”:130.9666666667,”f”:null},{“v”:10.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/02/2014″,”f”:null},{“v”:208,”f”:null},{“v”:227.6,”f”:null},{“v”:34.7833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/02/2014″,”f”:null},{“v”:260,”f”:null},{“v”:202.2333333333,”f”:null},{“v”:62.0166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/02/2014″,”f”:null},{“v”:172.5166666667,”f”:null},{“v”:244.65,”f”:null},{“v”:36.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/03/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/03/2014″,”f”:null},{“v”:294.25,”f”:null},{“v”:172.65,”f”:null},{“v”:45.5666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/03/2014″,”f”:null},{“v”:146,”f”:null},{“v”:270,”f”:null},{“v”:69.3666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/03/2014″,”f”:null},{“v”:179.0666666667,”f”:null},{“v”:297.0333333333,”f”:null},{“v”:23.4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/03/2014″,”f”:null},{“v”:147.0166666667,”f”:null},{“v”:238.1166666667,”f”:null},{“v”:76.4833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/03/2014″,”f”:null},{“v”:221.9833333333,”f”:null},{“v”:198.1,”f”:null},{“v”:48.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/03/2014″,”f”:null},{“v”:220.0166666667,”f”:null},{“v”:261.9833333333,”f”:null},{“v”:28,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/03/2014″,”f”:null},{“v”:151,”f”:null},{“v”:265.0166666667,”f”:null},{“v”:49.3166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/03/2014″,”f”:null},{“v”:186.0166666667,”f”:null},{“v”:185.9833333333,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/03/2014″,”f”:null},{“v”:149.2166666667,”f”:null},{“v”:334,”f”:null},{“v”:30.6666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/03/2014″,”f”:null},{“v”:172.45,”f”:null},{“v”:272,”f”:null},{“v”:27.7,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/03/2014″,”f”:null},{“v”:205,”f”:null},{“v”:215,”f”:null},{“v”:54.05,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/03/2014″,”f”:null},{“v”:224,”f”:null},{“v”:186.1,”f”:null},{“v”:44.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/03/2014″,”f”:null},{“v”:181,”f”:null},{“v”:219.4166666667,”f”:null},{“v”:23.4833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/03/2014″,”f”:null},{“v”:200.0166666667,”f”:null},{“v”:222.9833333333,”f”:null},{“v”:41.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/03/2014″,”f”:null},{“v”:119.0166666667,”f”:null},{“v”:234.8666666667,”f”:null},{“v”:41.9333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/03/2014″,”f”:null},{“v”:181,”f”:null},{“v”:260.1166666667,”f”:null},{“v”:42.05,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/03/2014″,”f”:null},{“v”:199.2,”f”:null},{“v”:253,”f”:null},{“v”:22.85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/03/2014″,”f”:null},{“v”:157.9833333333,”f”:null},{“v”:259.1333333333,”f”:null},{“v”:36.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/03/2014″,”f”:null},{“v”:184.0166666667,”f”:null},{“v”:271.9833333333,”f”:null},{“v”:43.35,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/03/2014″,”f”:null},{“v”:185.3833333333,”f”:null},{“v”:220,”f”:null},{“v”:42.2833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/03/2014″,”f”:null},{“v”:235,”f”:null},{“v”:227.0166666667,”f”:null},{“v”:34.45,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/03/2014″,”f”:null},{“v”:194.7833333333,”f”:null},{“v”:196.7666666667,”f”:null},{“v”:107.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/03/2014″,”f”:null},{“v”:228.9666666667,”f”:null},{“v”:215.9833333333,”f”:null},{“v”:26.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/03/2014″,”f”:null},{“v”:220.85,”f”:null},{“v”:184.85,”f”:null},{“v”:20.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/03/2014″,”f”:null},{“v”:183.0666666667,”f”:null},{“v”:233.8666666667,”f”:null},{“v”:33.8,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/03/2014″,”f”:null},{“v”:173.5666666667,”f”:null},{“v”:256.0666666667,”f”:null},{“v”:18,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/03/2014″,”f”:null},{“v”:231.0166666667,”f”:null},{“v”:185.9833333333,”f”:null},{“v”:31.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/03/2014″,”f”:null},{“v”:177,”f”:null},{“v”:226,”f”:null},{“v”:37.5333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/03/2014″,”f”:null},{“v”:221,”f”:null},{“v”:239.55,”f”:null},{“v”:71,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/03/2014″,”f”:null},{“v”:208.15,”f”:null},{“v”:174.4,”f”:null},{“v”:78.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/04/2014″,”f”:null},{“v”:161.0166666667,”f”:null},{“v”:293.9333333333,”f”:null},{“v”:31.0833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/04/2014″,”f”:null},{“v”:230.75,”f”:null},{“v”:216.8166666667,”f”:null},{“v”:49.4166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/04/2014″,”f”:null},{“v”:176.0166666667,”f”:null},{“v”:267.9833333333,”f”:null},{“v”:28.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/04/2014″,”f”:null},{“v”:182,”f”:null},{“v”:280,”f”:null},{“v”:35.8833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/04/2014″,”f”:null},{“v”:196.9833333333,”f”:null},{“v”:228.0166666667,”f”:null},{“v”:59.4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/04/2014″,”f”:null},{“v”:237.5666666667,”f”:null},{“v”:181.9833333333,”f”:null},{“v”:96.6,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/04/2014″,”f”:null},{“v”:239.0166666667,”f”:null},{“v”:149.9833333333,”f”:null},{“v”:60.0833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/04/2014″,”f”:null},{“v”:246,”f”:null},{“v”:223.15,”f”:null},{“v”:22.95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/04/2014″,”f”:null},{“v”:181.9666666667,”f”:null},{“v”:261,”f”:null},{“v”:34.8833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/04/2014″,”f”:null},{“v”:197.0166666667,”f”:null},{“v”:260.5,”f”:null},{“v”:21.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/04/2014″,”f”:null},{“v”:192.5166666667,”f”:null},{“v”:267.7333333333,”f”:null},{“v”:24.2833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/04/2014″,”f”:null},{“v”:213.2166666667,”f”:null},{“v”:256.9833333333,”f”:null},{“v”:25.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/04/2014″,”f”:null},{“v”:270,”f”:null},{“v”:194.1166666667,”f”:null},{“v”:36.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/04/2014″,”f”:null},{“v”:211.05,”f”:null},{“v”:241.95,”f”:null},{“v”:29.6,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/04/2014″,”f”:null},{“v”:234,”f”:null},{“v”:174.3,”f”:null},{“v”:28.6,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/04/2014″,”f”:null},{“v”:186.0333333333,”f”:null},{“v”:247.2666666667,”f”:null},{“v”:43.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/04/2014″,”f”:null},{“v”:203.0333333333,”f”:null},{“v”:226.75,”f”:null},{“v”:42.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/04/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/04/2014″,”f”:null},{“v”:176,”f”:null},{“v”:194,”f”:null},{“v”:43.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/04/2014″,”f”:null},{“v”:212,”f”:null},{“v”:239,”f”:null},{“v”:48.85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/04/2014″,”f”:null},{“v”:202.0166666667,”f”:null},{“v”:214.8166666667,”f”:null},{“v”:146.8833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/04/2014″,”f”:null},{“v”:206.8,”f”:null},{“v”:260,”f”:null},{“v”:17.95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/04/2014″,”f”:null},{“v”:199.75,”f”:null},{“v”:244.95,”f”:null},{“v”:41.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/04/2014″,”f”:null},{“v”:158,”f”:null},{“v”:275.3666666667,”f”:null},{“v”:22.1166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/04/2014″,”f”:null},{“v”:193.0166666667,”f”:null},{“v”:233.5166666667,”f”:null},{“v”:11.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/04/2014″,”f”:null},{“v”:152.0166666667,”f”:null},{“v”:349.9833333333,”f”:null},{“v”:37.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/04/2014″,”f”:null},{“v”:277,”f”:null},{“v”:194,”f”:null},{“v”:53.6166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/04/2014″,”f”:null},{“v”:171.0333333333,”f”:null},{“v”:284.9833333333,”f”:null},{“v”:27.4166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/04/2014″,”f”:null},{“v”:166.0166666667,”f”:null},{“v”:210.9833333333,”f”:null},{“v”:58.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/04/2014″,”f”:null},{“v”:241.2166666667,”f”:null},{“v”:150.9833333333,”f”:null},{“v”:53.45,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/05/2014″,”f”:null},{“v”:163,”f”:null},{“v”:250.7,”f”:null},{“v”:19.0666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/05/2014″,”f”:null},{“v”:183.0333333333,”f”:null},{“v”:246.9833333333,”f”:null},{“v”:40.6166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/05/2014″,”f”:null},{“v”:155.3,”f”:null},{“v”:272.9666666667,”f”:null},{“v”:36.2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/05/2014″,”f”:null},{“v”:129.4,”f”:null},{“v”:126.6166666667,”f”:null},{“v”:40.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/05/2014″,”f”:null},{“v”:251,”f”:null},{“v”:224.9833333333,”f”:null},{“v”:23.6166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/05/2014″,”f”:null},{“v”:233.1333333333,”f”:null},{“v”:186,”f”:null},{“v”:45.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/05/2014″,”f”:null},{“v”:140,”f”:null},{“v”:307.8833333333,”f”:null},{“v”:39.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/05/2014″,”f”:null},{“v”:168,”f”:null},{“v”:300.9,”f”:null},{“v”:16.85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/05/2014″,”f”:null},{“v”:155.0166666667,”f”:null},{“v”:233.4833333333,”f”:null},{“v”:37.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/05/2014″,”f”:null},{“v”:207.9666666667,”f”:null},{“v”:214,”f”:null},{“v”:68.5666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/05/2014″,”f”:null},{“v”:195.0166666667,”f”:null},{“v”:198.4166666667,”f”:null},{“v”:109.85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/05/2014″,”f”:null},{“v”:185.0333333333,”f”:null},{“v”:268.6666666667,”f”:null},{“v”:15.3166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/05/2014″,”f”:null},{“v”:186.0166666667,”f”:null},{“v”:207.3166666667,”f”:null},{“v”:79.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/05/2014″,”f”:null},{“v”:229.0166666667,”f”:null},{“v”:233.9833333333,”f”:null},{“v”:20.3166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/05/2014″,”f”:null},{“v”:215.0166666667,”f”:null},{“v”:219.1,”f”:null},{“v”:24.4333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/05/2014″,”f”:null},{“v”:173,”f”:null},{“v”:214.85,”f”:null},{“v”:22.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/05/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/05/2014″,”f”:null},{“v”:146,”f”:null},{“v”:274.2833333333,”f”:null},{“v”:28.15,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/05/2014″,”f”:null},{“v”:133.0166666667,”f”:null},{“v”:87.9833333333,”f”:null},{“v”:19.75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/05/2014″,”f”:null},{“v”:170,”f”:null},{“v”:236,”f”:null},{“v”:87.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/06/2014″,”f”:null},{“v”:189.5333333333,”f”:null},{“v”:274.2833333333,”f”:null},{“v”:72.35,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/06/2014″,”f”:null},{“v”:207.8166666667,”f”:null},{“v”:238.9833333333,”f”:null},{“v”:29.15,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/06/2014″,”f”:null},{“v”:172.0166666667,”f”:null},{“v”:222.0333333333,”f”:null},{“v”:74.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/06/2014″,”f”:null},{“v”:267.3166666667,”f”:null},{“v”:214.0166666667,”f”:null},{“v”:27.5333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/06/2014″,”f”:null},{“v”:228.7333333333,”f”:null},{“v”:144.9833333333,”f”:null},{“v”:26.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/06/2014″,”f”:null},{“v”:237.0166666667,”f”:null},{“v”:236.9833333333,”f”:null},{“v”:34.8333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/06/2014″,”f”:null},{“v”:225.0166666667,”f”:null},{“v”:245.9833333333,”f”:null},{“v”:6.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/06/2014″,”f”:null},{“v”:161,”f”:null},{“v”:111.0333333333,”f”:null},{“v”:41.1833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/06/2014″,”f”:null},{“v”:208,”f”:null},{“v”:243.5666666667,”f”:null},{“v”:16.4166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/06/2014″,”f”:null},{“v”:223.85,”f”:null},{“v”:231,”f”:null},{“v”:27.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/06/2014″,”f”:null},{“v”:160.8666666667,”f”:null},{“v”:313.95,”f”:null},{“v”:19.0166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/06/2014″,”f”:null},{“v”:300.0333333333,”f”:null},{“v”:144.9666666667,”f”:null},{“v”:25.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/06/2014″,”f”:null},{“v”:206,”f”:null},{“v”:207.9666666667,”f”:null},{“v”:45.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/06/2014″,”f”:null},{“v”:36,”f”:null},{“v”:45,”f”:null},{“v”:34.0833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/06/2014″,”f”:null},{“v”:191.9666666667,”f”:null},{“v”:269.35,”f”:null},{“v”:20.1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/06/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/06/2014″,”f”:null},{“v”:233.1333333333,”f”:null},{“v”:215.4333333333,”f”:null},{“v”:16.7166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/06/2014″,”f”:null},{“v”:171,”f”:null},{“v”:252.2833333333,”f”:null},{“v”:34.1833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/06/2014″,”f”:null},{“v”:161,”f”:null},{“v”:261,”f”:null},{“v”:34.75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/06/2014″,”f”:null},{“v”:205.2833333333,”f”:null},{“v”:257,”f”:null},{“v”:39.2666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/06/2014″,”f”:null},{“v”:170.9666666667,”f”:null},{“v”:311.65,”f”:null},{“v”:23.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/06/2014″,”f”:null},{“v”:165.3666666667,”f”:null},{“v”:256.9833333333,”f”:null},{“v”:41.4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/06/2014″,”f”:null},{“v”:185.25,”f”:null},{“v”:267.8333333333,”f”:null},{“v”:30.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/06/2014″,”f”:null},{“v”:140,”f”:null},{“v”:270.7166666667,”f”:null},{“v”:43.2833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/06/2014″,”f”:null},{“v”:189.7166666667,”f”:null},{“v”:255,”f”:null},{“v”:16.7833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/06/2014″,”f”:null},{“v”:170,”f”:null},{“v”:261.1,”f”:null},{“v”:33.5833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/06/2014″,”f”:null},{“v”:138,”f”:null},{“v”:307.2,”f”:null},{“v”:21.2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/06/2014″,”f”:null},{“v”:173.5666666667,”f”:null},{“v”:146.0666666667,”f”:null},{“v”:63.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/06/2014″,”f”:null},{“v”:208,”f”:null},{“v”:342.1333333333,”f”:null},{“v”:12.3166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/06/2014″,”f”:null},{“v”:200,”f”:null},{“v”:187.5833333333,”f”:null},{“v”:13.4666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/07/2014″,”f”:null},{“v”:258.2833333333,”f”:null},{“v”:189.6166666667,”f”:null},{“v”:24.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/07/2014″,”f”:null},{“v”:181.0333333333,”f”:null},{“v”:229.1666666667,”f”:null},{“v”:20.8333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/07/2014″,”f”:null},{“v”:134.0166666667,”f”:null},{“v”:275.3166666667,”f”:null},{“v”:30.5666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/07/2014″,”f”:null},{“v”:218,”f”:null},{“v”:195.3166666667,”f”:null},{“v”:21.2833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/07/2014″,”f”:null},{“v”:230.4833333333,”f”:null},{“v”:160.2666666667,”f”:null},{“v”:53.0333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/07/2014″,”f”:null},{“v”:191,”f”:null},{“v”:178.7666666667,”f”:null},{“v”:18.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/07/2014″,”f”:null},{“v”:214,”f”:null},{“v”:222.95,”f”:null},{“v”:25.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/07/2014″,”f”:null},{“v”:176.1833333333,”f”:null},{“v”:245,”f”:null},{“v”:44.95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/07/2014″,”f”:null},{“v”:176.9666666667,”f”:null},{“v”:216.0833333333,”f”:null},{“v”:36,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/07/2014″,”f”:null},{“v”:185,”f”:null},{“v”:204.5166666667,”f”:null},{“v”:36.7333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/07/2014″,”f”:null},{“v”:186,”f”:null},{“v”:111.95,”f”:null},{“v”:56.6833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/07/2014″,”f”:null},{“v”:237.0166666667,”f”:null},{“v”:173,”f”:null},{“v”:68.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/07/2014″,”f”:null},{“v”:259.5833333333,”f”:null},{“v”:157.2833333333,”f”:null},{“v”:54.25,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/07/2014″,”f”:null},{“v”:155.5166666667,”f”:null},{“v”:263,”f”:null},{“v”:59.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/07/2014″,”f”:null},{“v”:220.0166666667,”f”:null},{“v”:266.65,”f”:null},{“v”:53.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/07/2014″,”f”:null},{“v”:220.0166666667,”f”:null},{“v”:276.7166666667,”f”:null},{“v”:26.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/07/2014″,”f”:null},{“v”:196.0166666667,”f”:null},{“v”:275.7333333333,”f”:null},{“v”:28.0333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/07/2014″,”f”:null},{“v”:260,”f”:null},{“v”:97,”f”:null},{“v”:89.55,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/07/2014″,”f”:null},{“v”:257.4166666667,”f”:null},{“v”:203,”f”:null},{“v”:81.7166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/07/2014″,”f”:null},{“v”:274.0166666667,”f”:null},{“v”:217.9833333333,”f”:null},{“v”:39.4333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/07/2014″,”f”:null},{“v”:186,”f”:null},{“v”:276.9,”f”:null},{“v”:29.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/07/2014″,”f”:null},{“v”:255.05,”f”:null},{“v”:228.9833333333,”f”:null},{“v”:38.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/07/2014″,”f”:null},{“v”:208,”f”:null},{“v”:255.2666666667,”f”:null},{“v”:40.0333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/07/2014″,”f”:null},{“v”:197,”f”:null},{“v”:204.6166666667,”f”:null},{“v”:64.25,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/07/2014″,”f”:null},{“v”:210,”f”:null},{“v”:273,”f”:null},{“v”:45.1166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/07/2014″,”f”:null},{“v”:203.8,”f”:null},{“v”:216.9833333333,”f”:null},{“v”:105.3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/07/2014″,”f”:null},{“v”:252.0166666667,”f”:null},{“v”:231.9833333333,”f”:null},{“v”:49.4333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/07/2014″,”f”:null},{“v”:124.4333333333,”f”:null},{“v”:327.9833333333,”f”:null},{“v”:81.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/07/2014″,”f”:null},{“v”:185.0166666667,”f”:null},{“v”:128.8333333333,”f”:null},{“v”:148.5666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/07/2014″,”f”:null},{“v”:234.5333333333,”f”:null},{“v”:229.7,”f”:null},{“v”:103.4166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/07/2014″,”f”:null},{“v”:202.05,”f”:null},{“v”:325.9,”f”:null},{“v”:55.7333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/08/2014″,”f”:null},{“v”:251.0333333333,”f”:null},{“v”:172.85,”f”:null},{“v”:28.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/08/2014″,”f”:null},{“v”:228.05,”f”:null},{“v”:117.9166666667,”f”:null},{“v”:122.9333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/08/2014″,”f”:null},{“v”:179.75,”f”:null},{“v”:214.9833333333,”f”:null},{“v”:35.9,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/08/2014″,”f”:null},{“v”:253,”f”:null},{“v”:256.8833333333,”f”:null},{“v”:42.55,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/08/2014″,”f”:null},{“v”:142.0166666667,”f”:null},{“v”:285.6166666667,”f”:null},{“v”:24.45,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/08/2014″,”f”:null},{“v”:230.1,”f”:null},{“v”:208.9833333333,”f”:null},{“v”:55.2666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/08/2014″,”f”:null},{“v”:215,”f”:null},{“v”:211,”f”:null},{“v”:45.2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/08/2014″,”f”:null},{“v”:234.9833333333,”f”:null},{“v”:216.3833333333,”f”:null},{“v”:20.55,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/08/2014″,”f”:null},{“v”:211,”f”:null},{“v”:234.2666666667,”f”:null},{“v”:20.4666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/08/2014″,”f”:null},{“v”:201.9833333333,”f”:null},{“v”:208,”f”:null},{“v”:54.1166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/08/2014″,”f”:null},{“v”:239.3833333333,”f”:null},{“v”:169.6666666667,”f”:null},{“v”:58.0166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/08/2014″,”f”:null},{“v”:175,”f”:null},{“v”:227.55,”f”:null},{“v”:73.75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/08/2014″,”f”:null},{“v”:192.0166666667,”f”:null},{“v”:257.5166666667,”f”:null},{“v”:27.6666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/08/2014″,”f”:null},{“v”:179.6,”f”:null},{“v”:239.8333333333,”f”:null},{“v”:66.5833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/08/2014″,”f”:null},{“v”:116.2833333333,”f”:null},{“v”:289.9,”f”:null},{“v”:27.8166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/08/2014″,”f”:null},{“v”:154,”f”:null},{“v”:209,”f”:null},{“v”:55.2666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/08/2014″,”f”:null},{“v”:177.5833333333,”f”:null},{“v”:265,”f”:null},{“v”:21.9,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/08/2014″,”f”:null},{“v”:196,”f”:null},{“v”:225.35,”f”:null},{“v”:29.5833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/08/2014″,”f”:null},{“v”:182.7166666667,”f”:null},{“v”:189.7,”f”:null},{“v”:61.8833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/08/2014″,”f”:null},{“v”:263,”f”:null},{“v”:188.7166666667,”f”:null},{“v”:28.7666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/08/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/09/2014″,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/09/2014″,”f”:null},{“v”:215.6166666667,”f”:null},{“v”:203.4,”f”:null},{“v”:30.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/09/2014″,”f”:null},{“v”:175.05,”f”:null},{“v”:270,”f”:null},{“v”:31.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/09/2014″,”f”:null},{“v”:197,”f”:null},{“v”:228,”f”:null},{“v”:87.5166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/09/2014″,”f”:null},{“v”:196.0333333333,”f”:null},{“v”:239.9666666667,”f”:null},{“v”:28.3666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/09/2014″,”f”:null},{“v”:151.0166666667,”f”:null},{“v”:297.9833333333,”f”:null},{“v”:27.4666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/09/2014″,”f”:null},{“v”:182.9833333333,”f”:null},{“v”:261.1166666667,”f”:null},{“v”:21.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/09/2014″,”f”:null},{“v”:216,”f”:null},{“v”:260.9,”f”:null},{“v”:19.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/09/2014″,”f”:null},{“v”:224.5,”f”:null},{“v”:208.5666666667,”f”:null},{“v”:73.35,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/09/2014″,”f”:null},{“v”:180.1,”f”:null},{“v”:248,”f”:null},{“v”:51.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/09/2014″,”f”:null},{“v”:170.0166666667,”f”:null},{“v”:298,”f”:null},{“v”:32.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/09/2014″,”f”:null},{“v”:228.45,”f”:null},{“v”:226.9833333333,”f”:null},{“v”:43.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/09/2014″,”f”:null},{“v”:139.7833333333,”f”:null},{“v”:298.15,”f”:null},{“v”:36.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/09/2014″,”f”:null},{“v”:184.0166666667,”f”:null},{“v”:259,”f”:null},{“v”:34.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/09/2014″,”f”:null},{“v”:206,”f”:null},{“v”:231.95,”f”:null},{“v”:78.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/09/2014″,”f”:null},{“v”:200.8,”f”:null},{“v”:249.9833333333,”f”:null},{“v”:22.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/09/2014″,”f”:null},{“v”:218,”f”:null},{“v”:224.6833333333,”f”:null},{“v”:27.0666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/09/2014″,”f”:null},{“v”:227.0333333333,”f”:null},{“v”:255.5166666667,”f”:null},{“v”:37.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/09/2014″,”f”:null},{“v”:223,”f”:null},{“v”:221.7833333333,”f”:null},{“v”:99.4833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/09/2014″,”f”:null},{“v”:178.0166666667,”f”:null},{“v”:290.75,”f”:null},{“v”:23.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/09/2014″,”f”:null},{“v”:164.6666666667,”f”:null},{“v”:259,”f”:null},{“v”:44.5166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/10/2014″,”f”:null},{“v”:192.0166666667,”f”:null},{“v”:203.6,”f”:null},{“v”:50.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/10/2014″,”f”:null},{“v”:276,”f”:null},{“v”:152.6166666667,”f”:null},{“v”:102.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/10/2014″,”f”:null},{“v”:279,”f”:null},{“v”:141.7666666667,”f”:null},{“v”:38.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/10/2014″,”f”:null},{“v”:225.0833333333,”f”:null},{“v”:216,”f”:null},{“v”:85.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/10/2014″,”f”:null},{“v”:190,”f”:null},{“v”:176.1,”f”:null},{“v”:45.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/10/2014″,”f”:null},{“v”:238.9666666667,”f”:null},{“v”:189.9833333333,”f”:null},{“v”:50.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/10/2014″,”f”:null},{“v”:165.75,”f”:null},{“v”:282.5333333333,”f”:null},{“v”:75.6666666667,”f”:null}xxx01xxx}xxx01xxx,”p”:null},”options”:{“legend”:”right”,”title”:”Sleep time (minutes)”,”isStacked”:true,”vAxes”:xxx00xxx{“title”:null,”minValue”:null,”maxValue”:null,”viewWindow”:{“max”:null,”min”:null},”logScale”:false,”useFormatFromData”:true},{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”logScale”:false,”useFormatFromData”:true}xxx01xxx,”animation”:{“duration”:500},”booleanRole”:”certainty”,”hAxis”:{“useFormatFromData”:true,”minValue”:null,”maxValue”:null,”viewWindow”:null,”viewWindowMode”:null,”title”:”Date”},”focusTarget”:”category”,”series”:{“0”:{“color”:”#00b1b1″,”areaOpacity”:”1.0″},”1″:{“color”:”#ff9900″,”areaOpacity”:”0.5″},”2″:{“color”:”#cc0000″,”areaOpacity”:”0.5″}}},”state”:{},”view”:{},”isDefaultVisualization”:false,”chartType”:”AreaChart”}’ ]
[chartboot version= ‘3.0’ code= ‘137F’ border= ‘1’ width= ‘800’ height= ‘400’ attribution= ‘1’ jsondesc= ‘{“containerId”:”visualization137F”,”dataTable”:{“cols”:xxx00xxx{“id”:””,”label”:”Date”,”pattern”:””,”type”:”string”,”p”:{}},{“id”:””,”label”:”Sleep quality metric”,”pattern”:””,”type”:”number”}xxx01xxx,”rows”:xxx00xxx{“c”:xxx00xxx{“v”:”01/01/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/01/2014″,”f”:null},{“v”:68,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/01/2014″,”f”:null},{“v”:72,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/01/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/01/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/01/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/01/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/01/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/01/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/01/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/01/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/01/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/01/2014″,”f”:null},{“v”:71,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/01/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/01/2014″,”f”:null},{“v”:72,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/01/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/01/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/01/2014″,”f”:null},{“v”:97,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/02/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/02/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/02/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/02/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/02/2014″,”f”:null},{“v”:84,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/02/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/02/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/02/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/02/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/02/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/02/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/02/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/02/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/02/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/02/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/02/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/02/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/02/2014″,”f”:null},{“v”:91,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/02/2014″,”f”:null},{“v”:75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/02/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/02/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/02/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/02/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/02/2014″,”f”:null},{“v”:94,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/02/2014″,”f”:null},{“v”:59,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/02/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/02/2014″,”f”:null},{“v”:99,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/02/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/03/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/03/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/03/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/03/2014″,”f”:null},{“v”:91,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/03/2014″,”f”:null},{“v”:74,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/03/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/03/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/03/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/03/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/03/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/03/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/03/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/03/2014″,”f”:null},{“v”:65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/03/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/03/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/03/2014″,”f”:null},{“v”:91,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/03/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/03/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/03/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/03/2014″,”f”:null},{“v”:91,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/03/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/03/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/03/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/03/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/03/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/03/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/04/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/04/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/04/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/04/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/04/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/04/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/04/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/04/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/04/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/04/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/04/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/04/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/04/2014″,”f”:null},{“v”:98,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/04/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/04/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/04/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/04/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/04/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/04/2014″,”f”:null},{“v”:73,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/04/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/04/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/04/2014″,”f”:null},{“v”:91,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/04/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/04/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/04/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/04/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/04/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/04/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/04/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/04/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/05/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/05/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/05/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/05/2014″,”f”:null},{“v”:50,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/05/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/05/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/05/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/05/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/05/2014″,”f”:null},{“v”:74,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/05/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/05/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/05/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/05/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/05/2014″,”f”:null},{“v”:97,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/05/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/05/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/05/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/05/2014″,”f”:null},{“v”:49,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/05/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/06/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/06/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/06/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/06/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/06/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/06/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/06/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/06/2014″,”f”:null},{“v”:58,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/06/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/06/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/06/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/06/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/06/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/06/2014″,”f”:null},{“v”:16,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/06/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/06/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/06/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/06/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/06/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/06/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/06/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/06/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/06/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/06/2014″,”f”:null},{“v”:75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/06/2014″,”f”:null},{“v”:84,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/06/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/06/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/06/2014″,”f”:null},{“v”:69,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/06/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/06/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/07/2014″,”f”:null},{“v”:99,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/07/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/07/2014″,”f”:null},{“v”:74,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/07/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/07/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/07/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/07/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/07/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/07/2014″,”f”:null},{“v”:78,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/07/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/07/2014″,”f”:null},{“v”:67,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/07/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/07/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/07/2014″,”f”:null},{“v”:75,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/07/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/07/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/07/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/07/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/07/2014″,”f”:null},{“v”:97,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/07/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/07/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/07/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/07/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/07/2014″,”f”:null},{“v”:84,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/07/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/07/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/07/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/07/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/07/2014″,”f”:null},{“v”:67,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/07/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/07/2014″,”f”:null},{“v”:98,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/08/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/08/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/08/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/08/2014″,”f”:null},{“v”:100,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/08/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/08/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/08/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/08/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/08/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/08/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/08/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/08/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/08/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/08/2014″,”f”:null},{“v”:79,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/08/2014″,”f”:null},{“v”:72,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/08/2014″,”f”:null},{“v”:70,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/08/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/08/2014″,”f”:null},{“v”:85,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/08/2014″,”f”:null},{“v”:77,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/08/2014″,”f”:null},{“v”:97,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/09/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/09/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/09/2014″,”f”:null},{“v”:80,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/09/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/09/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/09/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/09/2014″,”f”:null},{“v”:98,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/09/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/09/2014″,”f”:null},{“v”:82,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/09/2014″,”f”:null},{“v”:86,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/09/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/09/2014″,”f”:null},{“v”:76,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/09/2014″,”f”:null},{“v”:87,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/09/2014″,”f”:null},{“v”:88,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/09/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/09/2014″,”f”:null},{“v”:92,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/09/2014″,”f”:null},{“v”:96,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/09/2014″,”f”:null},{“v”:94,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/09/2014″,”f”:null},{“v”:90,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/09/2014″,”f”:null},{“v”:81,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/10/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/10/2014″,”f”:null},{“v”:97,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/10/2014″,”f”:null},{“v”:95,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/10/2014″,”f”:null},{“v”:89,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/10/2014″,”f”:null},{“v”:74,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/10/2014″,”f”:null},{“v”:93,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/10/2014″,”f”:null},{“v”:83,”f”:null}xxx01xxx}xxx01xxx,”p”:null},”options”:{“legend”:”none”,”title”:”Sleep quality”,”vAxes”:xxx00xxx{“title”:”Sleep quality measure”,”minValue”:null,”maxValue”:null,”viewWindow”:{“max”:null,”min”:null},”useFormatFromData”:false,”logScale”:false,”formatOptions”:{“source”:”inline”},”format”:”0.##”},{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”useFormatFromData”:true}xxx01xxx,”animation”:{“duration”:500},”booleanRole”:”certainty”,”lineWidth”:2,”hAxis”:{“minValue”:null,”maxValue”:null,”viewWindow”:null,”viewWindowMode”:null,”useFormatFromData”:true,”title”:”Date”},”curveType”:””,”series”:{“0”:{“color”:”#cc0000″}}},”state”:{},”view”:{},”isDefaultVisualization”:false,”chartType”:”LineChart”}’ ]
[chartboot version= ‘3.0’ code= ‘6BAC’ border= ‘1’ width= ‘800’ height= ‘400’ attribution= ‘1’ jsondesc= ‘{“containerId”:”visualization6BAC”,”dataTable”:{“cols”:xxx00xxx{“id”:””,”label”:”Date”,”pattern”:””,”type”:”string”,”p”:{}},{“id”:””,”label”:”Number of awakenings”,”pattern”:””,”type”:”number”}xxx01xxx,”rows”:xxx00xxx{“c”:xxx00xxx{“v”:”01/01/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/01/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/01/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/01/2014″,”f”:null},{“v”:5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/01/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/01/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/01/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/01/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/02/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/02/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/02/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/02/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/02/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/02/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/02/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/02/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/02/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/03/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/03/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/03/2014″,”f”:null},{“v”:5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/03/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/03/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/03/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/03/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/04/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/04/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/04/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/04/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/04/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/04/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/04/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/04/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/04/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/05/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/05/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/05/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/05/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/05/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/05/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/05/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/05/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/05/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/05/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/05/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/05/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/06/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/06/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/06/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/06/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/06/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/06/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/06/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/06/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/06/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/07/2014″,”f”:null},{“v”:5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/07/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/07/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/07/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/07/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/08/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/08/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/08/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/08/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/08/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/08/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/08/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”31/08/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”08/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”09/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”10/09/2014″,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”11/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/09/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/09/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/09/2014″,”f”:null},{“v”:0,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/09/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/09/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/09/2014″,”f”:null},{“v”:1,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/10/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/10/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/10/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/10/2014″,”f”:null},{“v”:4,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/10/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/10/2014″,”f”:null},{“v”:2,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/10/2014″,”f”:null},{“v”:3,”f”:null}xxx01xxx}xxx01xxx,”p”:null},”options”:{“legend”:”none”,”title”:”Number of night-time awakenings”,”isStacked”:false,”vAxes”:xxx00xxx{“title”:”Count of awakenings”,”minValue”:null,”maxValue”:null,”viewWindow”:{“max”:null,”min”:null},”useFormatFromData”:true},{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”useFormatFromData”:true}xxx01xxx,”animation”:{“duration”:500},”booleanRole”:”certainty”,”hAxis”:{“minValue”:null,”maxValue”:null,”viewWindow”:null,”viewWindowMode”:null,”useFormatFromData”:true,”title”:”Date”},”series”:{“0”:{“color”:”#ff9900″}}},”state”:{},”view”:{},”isDefaultVisualization”:false,”chartType”:”ColumnChart”}’ ]
Stage 4: Question the data
There are some immediate observations that come from the graphs above:
- There are a lot of gaps in the data – This is due to the Jawbone UP breaking and being sent away for repair/replacement. Given that, I’m happy to treat the data as missing completely at random, which makes life a lot easier
- The sleep quality measure peaks out at 100 fairly regularly – This is called a ceiling effect, and makes the data less useful. Given that and the fact that I don’t understand the measure itself, I’m tempted to avoid analysing it
- The sleep duration data does appear to vary around some fairly consistent average values
- The big one – I can’t see any dramatic change in sleep pattern
Let’s concentrate on that final observation. When I first got this data, I thought it would be a great opportunity to show a good analytic approach. After all, it’s pretty obvious that stopping caffeine will improve sleep. Right?
Hmmm. The thing is, I don’t actually know when my brother drinks his coffee. Maybe he’s a morning addict and it’s all out of his system by the time he goes to bed. Maybe the caffeine-free diet doesn’t benefit his sleep at all. We have to accept that, maybe, the caffeine isn’t really affecting his sleep.
I still haven’t mentioned when my brother stopped caffeine. His last caffeine was on 27th September. That’s quite late in the graphs above, so maybe that’s hiding some of the effect, if there is one. It also means that we only have a little data after the change. Here’s some detail from that period:
[chartboot version= ‘3.0’ code= ‘1B1C’ border= ‘1’ width= ‘800’ height= ‘400’ attribution= ‘1’ jsondesc= ‘{“containerId”:”visualization1B1C”,”dataTable”:{“cols”:xxx00xxx{“id”:””,”label”:”Date”,”pattern”:””,”type”:”string”,”p”:{}},{“id”:””,”label”:”Deep sleep duration (minutes)”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Light sleep duration”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Night waking duration (minutes)”,”pattern”:””,”type”:”number”}xxx01xxx,”rows”:xxx00xxx{“c”:xxx00xxx{“v”:”11/09/2014″,”f”:null},{“v”:215.6166666667,”f”:null},{“v”:203.4,”f”:null},{“v”:30.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”12/09/2014″,”f”:null},{“v”:175.05,”f”:null},{“v”:270,”f”:null},{“v”:31.1666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”13/09/2014″,”f”:null},{“v”:197,”f”:null},{“v”:228,”f”:null},{“v”:87.5166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”14/09/2014″,”f”:null},{“v”:196.0333333333,”f”:null},{“v”:239.9666666667,”f”:null},{“v”:28.3666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”15/09/2014″,”f”:null},{“v”:151.0166666667,”f”:null},{“v”:297.9833333333,”f”:null},{“v”:27.4666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”16/09/2014″,”f”:null},{“v”:182.9833333333,”f”:null},{“v”:261.1166666667,”f”:null},{“v”:21.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”17/09/2014″,”f”:null},{“v”:216,”f”:null},{“v”:260.9,”f”:null},{“v”:19.65,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”18/09/2014″,”f”:null},{“v”:224.5,”f”:null},{“v”:208.5666666667,”f”:null},{“v”:73.35,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”19/09/2014″,”f”:null},{“v”:180.1,”f”:null},{“v”:248,”f”:null},{“v”:51.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”20/09/2014″,”f”:null},{“v”:170.0166666667,”f”:null},{“v”:298,”f”:null},{“v”:32.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”21/09/2014″,”f”:null},{“v”:228.45,”f”:null},{“v”:226.9833333333,”f”:null},{“v”:43.9166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”22/09/2014″,”f”:null},{“v”:139.7833333333,”f”:null},{“v”:298.15,”f”:null},{“v”:36.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”23/09/2014″,”f”:null},{“v”:184.0166666667,”f”:null},{“v”:259,”f”:null},{“v”:34.8666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”24/09/2014″,”f”:null},{“v”:206,”f”:null},{“v”:231.95,”f”:null},{“v”:78.3333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”25/09/2014″,”f”:null},{“v”:200.8,”f”:null},{“v”:249.9833333333,”f”:null},{“v”:22.9666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”26/09/2014″,”f”:null},{“v”:218,”f”:null},{“v”:224.6833333333,”f”:null},{“v”:27.0666666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”27/09/2014″,”f”:null},{“v”:227.0333333333,”f”:null},{“v”:255.5166666667,”f”:null},{“v”:37.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”28/09/2014″,”f”:null},{“v”:223,”f”:null},{“v”:221.7833333333,”f”:null},{“v”:99.4833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”29/09/2014″,”f”:null},{“v”:178.0166666667,”f”:null},{“v”:290.75,”f”:null},{“v”:23.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”30/09/2014″,”f”:null},{“v”:164.6666666667,”f”:null},{“v”:259,”f”:null},{“v”:44.5166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”01/10/2014″,”f”:null},{“v”:192.0166666667,”f”:null},{“v”:203.6,”f”:null},{“v”:50.3833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”02/10/2014″,”f”:null},{“v”:276,”f”:null},{“v”:152.6166666667,”f”:null},{“v”:102.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”03/10/2014″,”f”:null},{“v”:279,”f”:null},{“v”:141.7666666667,”f”:null},{“v”:38.6333333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”04/10/2014″,”f”:null},{“v”:225.0833333333,”f”:null},{“v”:216,”f”:null},{“v”:85.2166666667,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”05/10/2014″,”f”:null},{“v”:190,”f”:null},{“v”:176.1,”f”:null},{“v”:45.5,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”06/10/2014″,”f”:null},{“v”:238.9666666667,”f”:null},{“v”:189.9833333333,”f”:null},{“v”:50.9833333333,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:”07/10/2014″,”f”:null},{“v”:165.75,”f”:null},{“v”:282.5333333333,”f”:null},{“v”:75.6666666667,”f”:null}xxx01xxx}xxx01xxx,”p”:null},”options”:{“legend”:”right”,”title”:”Sleep duration (detail of caffeine cessation)”,”isStacked”:true,”vAxes”:xxx00xxx{“title”:null,”minValue”:null,”maxValue”:null,”viewWindow”:{“max”:null,”min”:null},”logScale”:false,”useFormatFromData”:true},{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”logScale”:false,”useFormatFromData”:true}xxx01xxx,”animation”:{“duration”:500},”booleanRole”:”certainty”,”hAxis”:{“minValue”:null,”maxValue”:null,”viewWindow”:null,”viewWindowMode”:null,”useFormatFromData”:true,”title”:”Date”},”series”:{“0”:{“color”:”#00b1b1″,”areaOpacity”:”1.0″},”1″:{“color”:”#ff9900″,”areaOpacity”:”0.5″},”2″:{“color”:”#cc0000″,”areaOpacity”:”0.5″}}},”state”:{},”view”:{},”isDefaultVisualization”:false,”chartType”:”AreaChart”}’ ]
Overall, that makes me very doubtful that we have enough reliable data to come to a firm conclusion.
All is not lost, though.
We have discovered something fundamental about the human condition:
Humans see what they want, and expect, to see
My brother saw an effect, and I believed him, because it is logical that removing caffeine would affect sleep.What matters is that we have looked at the data, questioned it, and adjusted our expectations. That puts us in a position to ask realistic questions of the data.
Stage 5: Turn the question into an analytic question
One of the many things that puts people off engaging in research, I think, is that it is over-complicated because excessively complex statistical tests look at data in ways that are not immediately intuitive. Sometimes, this is necessary or appropriate. Most of the time, it isn’t.
We started with fairly simple question:
Does removing caffeine from his diet improve my brother’s sleep?
I’m now going to try and turn that into an analytic question. That’s a bit of jargon I use in teaching to distinguish between normal questions expressed in natural language and the slightly more specific questions we ask statistically. Basically, it means taking a question and expressing it in a way that allows us to explicitly assess hypotheses about the world (Bayesians note use of the word assess instead of test – please don’t get shouty).
In this case, we could start by refining two aspects of the question:
- Removing caffeine – In this case, we can only infer the effects of removing caffeine generally (i.e. any time my brother were to stop caffeine) from the specific instance we know about (the 27th September onwards)
- Improve – There are several ways, just looking at the sleep time data, that we could cut this. We could say ‘improve’ means ‘more sleep’. We could say it means ‘more deep sleep’, or we could say it means ‘a greater proportion of sleep is deep’. I didn’t know which one was important to my brother, so I asked. He said, ‘more deep sleep’ is his relevant definition
So, our initial analytic question is:
Did my brother experience more deep sleep per night once he had removed caffeine than he experienced previously?
As I’m sure you can see, there are two important features of this question:
- I could go on refining it forever (e.g. defining what I mean by ‘more’) without really making it a better question
- It doesn’t quite get at the point of interest
The second point there is key. The question as it currently stands is all about one event. We want to take information about that one event and make inferences from it about other events of the same class. In other words, we want to be able to say that, because there was a difference this time, we have reason to believe that there will be differences on future occasions. This inferential step should, in my opinion, be explicitly stated:
Given the change (if any) in deep sleep per night my brother experienced when he stopped taking caffeine, what can we infer about the effects of stopping caffeine on my brother’s deep sleep?
This change does make the question more complex, and a bit less transparent. For this reason, I like to answer the simple version first, then go on to the complex version. People are more likely to understand the analysis that way, I am less likely to make a silly mistake, and the world becomes just a little bit more straightforward.
Do note that, for a formal statistical analysis, you would need to be more precise because the analysis has to be open to independent interpretation. However, this is an analysis to help you make decisions, not to convince other people that your decisions are correct.
Stage 6: Do the analysis
As I said, we’ll start with the simple analysis, which is intended to answer the simple question. If we compare the average duration of deep sleep before and after stopping caffeine, we will see that the difference is not exactly astounding; the means are 198 and 213 minutes, and the medians are 197 and 208 minutes respectively.
If we look at the actual data plotted (rather crudely – a boxplot would be better), we can see that there is substantial overlap between the values after stopping caffeine and the values before stopping caffeine:
[chartboot version= ‘3.0’ code= ’54A4′ border= ‘1’ width= ‘800’ height= ‘400’ attribution= ‘1’ jsondesc= ‘{“containerId”:”visualization54A4″,”dataTable”:{“cols”:xxx00xxx{“id”:””,”label”:”Caffeine”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Deep sleep with caffeine”,”pattern”:””,”type”:”number”,”p”:{}},{“id”:””,”label”:”Deep sleep without caffeine”,”pattern”:””,”type”:”number”}xxx01xxx,”rows”:xxx00xxx{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:245,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:197,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:217,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:249,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:168,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:220,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:265,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:308,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:142,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:198,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:255,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:207,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:168,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:222,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:260,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:139,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:249,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:236,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:141,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:140,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:288,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:144,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:164,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:192,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:229,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:216,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:221,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:205,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:164,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:188,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:161,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:252,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:178,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:223,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:207,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:254,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:212,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:173,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:160,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:198,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:234,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:139,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:146,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:165,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:266,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:153,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:260,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:173,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:294,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:146,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:179,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:147,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:222,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:220,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:151,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:186,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:149,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:172,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:205,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:224,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:181,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:200,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:119,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:181,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:199,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:158,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:184,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:185,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:235,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:195,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:229,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:221,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:183,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:174,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:231,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:177,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:221,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:161,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:231,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:182,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:197,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:238,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:239,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:246,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:182,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:197,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:193,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:213,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:270,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:211,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:234,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:186,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:203,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:212,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:202,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:207,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:200,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:158,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:193,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:152,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:277,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:171,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:166,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:241,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:163,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:183,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:155,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:129,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:251,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:233,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:140,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:168,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:155,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:195,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:185,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:186,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:229,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:215,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:173,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:146,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:133,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:170,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:190,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:172,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:267,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:229,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:237,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:225,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:161,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:224,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:161,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:300,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:206,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:36,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:192,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:233,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:171,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:161,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:205,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:171,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:165,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:185,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:140,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:190,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:170,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:138,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:174,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:200,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:258,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:181,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:134,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:218,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:230,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:191,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:214,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:176,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:177,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:185,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:186,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:237,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:260,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:156,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:220,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:220,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:196,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:260,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:257,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:274,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:186,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:255,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:208,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:197,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:210,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:204,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:252,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:124,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:185,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:235,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:202,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:251,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:228,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:180,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:253,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:142,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:230,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:215,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:235,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:211,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:202,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:239,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:175,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:192,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:180,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:116,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:154,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:178,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:196,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:183,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:263,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:216,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:175,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:197,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:196,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:151,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:183,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:216,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:225,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:180,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:170,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:228,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:140,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:184,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:206,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:201,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:218,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:0,”f”:null},{“v”:227,”f”:null},{“v”:null,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:223,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:178,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:165,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:192,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:276,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:279,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:225,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:190,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:239,”f”:null}xxx01xxx},{“c”:xxx00xxx{“v”:1,”f”:null},{“v”:null,”f”:null},{“v”:166,”f”:null}xxx01xxx}xxx01xxx,”p”:null},”options”:{“legend”:”right”,”title”:”Number of minutes of deep sleep”,”animation”:{“duration”:500},”lineWidth”:0,”booleanRole”:”certainty”,”pointSize”:7,”vAxes”:xxx00xxx{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”useFormatFromData”:true,”title”:”Number of minutes”},{“viewWindow”:{“max”:null,”min”:null},”minValue”:null,”maxValue”:null,”useFormatFromData”:true}xxx01xxx,”hAxis”:{“viewWindow”:{“max”:1.5,”min”:-0.5},”useFormatFromData”:false,”minValue”:-0.5,”maxValue”:1.5,”viewWindowMode”:”explicit”,”title”:””,”gridlines”:{“color”:”none”},”textStyle”:{“color”:”none”,”fontSize”:12},”logScale”:false,”formatOptions”:{“source”:”inline”,”scaleFactor”:null},”format”:”0.##”},”series”:{“0”:{“color”:”#00b1b1″},”1″:{“color”:”#cc0000″}}},”state”:{},”isDefaultVisualization”:true,”chartType”:”ScatterChart”}’ ]
Based on this alone, my brother might have enough information to make a decision about his caffeine use. A rational person would say that the effect, if any, is probably around 10-15 minutes of additional deep sleep a night without caffeine, and even that is rather uncertain.
Let’s see if we can be a bit more precise than that.
One way of answering our question is to use bootstrapping. This involves taking samples from the data we already have and using them to make inferences about a larger data set. These data are ideal for this approach because:
- We have lots of baseline data – That is, we have a lot of data from when my brother was using caffeine, so we can generate reliable samples from this
- I don’t want to make distributional assumptions – The data look fairly normally distributed around a mean value, but I don’t want to make any assumptions about this
- I don’t want to lose individual detail – This is important. I don’t need to generalise my findings to other people, just to my brother’s sleep more generally. Given the amount of data we have, I want to use it and capture his idiosyncrasies rather than work around them
As we are using bootstrapping, we can make the analytic question even more specific:
If I took any random sample of ten days’ sleep data from the period before he stopped caffeine, what is the chance that I would see a pattern at least as extreme as my brother saw?
I’m going to do this analysis in R, which is free and can be used by anyone. There are packages available that allow us to do this analysis without coding, but I’m doing it long-hand because it is both easy and more transparent. I also want to show that statistical programming should be kept as simple as possible so that a mere mortal may read it.
First of all, we open the programme and set our working directory:
setwd("/home/Monkey/Experiments")
Then we import data from before caffeine cessation. In this case I have it as a nice comma separated file:
withcaff <- read.csv("deepsleepbeforecaffeine.csv", header=T)
This gives you a thing called a data frame object, which won’t work properly later on. Therefore, we need to change it into a vector (i.e. a simple list of numbers):
withcaff <- as.vector(withcaff[,1])
As you can see, I am calling this data object withcaff.
We are interested in looking at the likelihood of observing our data given what we already know about my brother’s sleep patterns. Specifically, we want to know what the likelihood is of seeing the mean and median deep sleep times we observed after caffeine cessation. To do that, R needs to know what the median and mean values were:
criticalmean <- c(213) criticalmedian <- c(208)
What we’re going to do now is find out the likelihood of observing these values or more extreme ones given the data we have on my brother’s sleep before he stopped taking caffeine.
We now specify the number of samples we want to take. I’m going to take a wild stab and go for 10,000.
A <- c(10000)
Then, we create a couple of objects to hold the results of our sampling:
meanvalues <- c() medianvalues <- c() length(meanvalues) <- A length(medianvalues) <- A
Once we have done this, we can simply repeatedly sample from the data we have and record the mean and median values in our vectors. Our post-caffeine sample was of 10 days’ sleep, so I will take lots of samples of size 10.
I am using a for loop to do this. It simply runs a set of commands a set number of times. In this case, it is running it A times (i.e. 10,000 times). For loops are often considered bad practice in R, but I don’t care – it’s clearer doing it this way and I can wait a few seconds for the analysis to run:
for (i in 1:A) {
randomsamples <- sample(withcaff, size=10,replace=T)
medianvalues[i] <- median(randomsamples)
meanvalues[i] <- mean(randomsamples)
}
Now we have the data, we can look at the likelihood of seeing the sleep times we actually saw, by just counting:
pmedian <- (sum(medianvalues>=criticalmedian))/A pmean <- (sum(meanvalues>=criticalmean))/A
The pmedian I get is 0.2268.
This can be interpreted as:
Given what we know about my brother’s sleep, our best guess of the chance that any ten day period has a median deep sleep value of at least 208 minutes is approximately 0.23, or 23 percent.
The pmean I get is 0.1167.
We could also look at the results of our analysis using a histogram:
hist(medianvalues, breaks=50) abline(v=criticalmedian, col='red')
The histograms look like this:

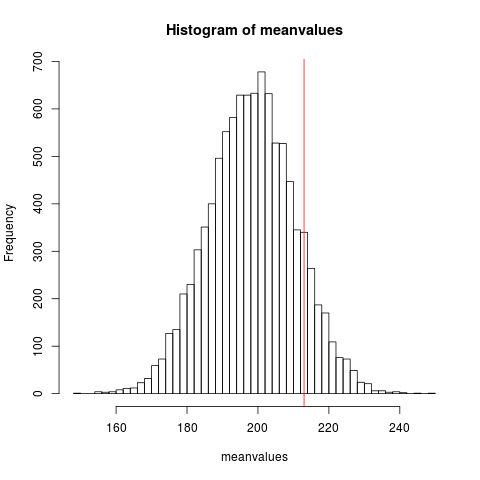
The net result of all of this is that stopping caffeine may have affected my brother’s deep sleep a bit, but we cannot be very sure about this.
Stage 7: Next steps
My brother started taking caffeine again. I could have discussed with him how much more data he would need to make a more certain decision. This is actually quite an easy thing to do, particularly with a bootstrapping approach. However, he decided against bothering. Why?
Well, he did have some withdrawal effects; a little weight gain and irritability. These may well have passed with time (I would certainly expect them to). More importantly, though, he just didn’t see the benefit in proportion to the disbenefit (or cost) of stopping caffeine. Ultimately, that balance is what ends up guiding our decisions. The role of statistics in this situation should be to inform that decision.
I hope this has shown you some approaches to looking at data about yourself. It is perfectly possible to analyse this data at home and use those analyses to inform your own decisions. The statistics involved do not need to be complex.
In this particular case, we could see the data clearly and honestly and use that to temper the preconceptions we had about the effects of caffeine to help my brother make a better decision that he could justify to himself.
What do you think? How do you look at data from your wearables?
This article also highlights a very important point that everyone should consider when making an intervention: what should I measure and why?
Caffeine, has multiple pathways of action, known and probably unknown. Are we measuring the right things? Is sleep quality and quantity the only factor? This is true of all interventions – multiple pathways, multiple points of measurement. Also, each individual will vary in the order of preference in what they think is important to their wellbeing.
This is a hugely important point, and thanks for making it.
As I wrote this, I noticed that the issue of measurement and outcomes comes out quite strongly. You’ll see from some of the other posts (e.g. https://monkeyglandin.com/why-are-drugs-so-disappointing/) that the issue of where on the causal chain you measure, and how you measure is something that is both challenging and important.
Sleep, for a lot of people, would be the relevant outcome. For my brother, it wasn’t the main outcome of interest. However, even if sleep were the main outcome of interest (e.g. in a clinical sleep study) we should still have some theory about the mode of action for caffeine. We can then use the sleep data to assess our theory, as well as other intermediate measures.
The really cool thing is that, if we select the right measures, we might be able to identify people who would, and would not, benefit from reducing caffeine. For example, we might look at the effect of timing of caffeine use, or we might look at adenosine receptors (one site of action for caffeine) or even caffeine metabolites to see if people that metabolise it better experience fewer sleep problems.
This may all sound a bit like you need lots of kit, but there are things you can do at home. For example, the metabolites of caffeine appear to be involved in heart rate effects. Given that, it may be possible to correlate changes in heart rate following consumption with sleep effects on the same day.
This all gets too complicated very quickly, which is why I suggest concentrating on what you want to achieve and why you think that will happen. This allows you to build questions that are targeted and can actually be answered sensibly.
Thanks for reading – let me know if there’s anything you’d particularly like to read about!
In some people with ADD/ADHD, sialumtnts such as caffeine can have a calming effect enough so that they can fall asleep. The principle is that in a person who has ADD, their thoughts are jumping around from one to another, constantly engaging the brain in mental activity. But sialumtnts help a person with ADD concentrate one just one or a few things. So that they can concentrate on relaxing more to the point where they fall asleep more easily.Also CNS like caffeine sometimes have the opposite effect in children, but I haven’t heard of a theory as to why.
I haven’t seen a comprehensive explanation of the paradoxical effects of stimulants in ADD/ADHD. They’ve been reported since before the second World War, so I’m comfortable assuming that they are real!
It’s worth noting that things like sleep-wake cycles and stimulation/arousal are often non-linear because they are controlled by multiple interacting systems. Typically, these involve quite complex nerve pathways between the cortex (the external part of the brain) and the subcortical areas (the bits in the middle near the brainstem) that are involved in basic life functions.
In case the idea of competing systems is counterintuitive, the way I think about it is that small children are often highly over-active just before they fall asleep to the extent that you can almost see the arousal and sleepiness systems competing, resulting in clumsy running about etc just before sleep. Indeed, they’re often most overactive when they’re most tired, presumably because the two (or more) balancing systems get out of step with each other.
I don’t know, but I suspect the apparently paradoxical effects of stimulants are related to this. This might also explain why there appear to be subgroups of people with ADD/ADHD who do not respond to standard stimulant therapy – different people might have difficulties with different parts of the interacting systems.
Sorry I can’t be more useful – if anyone else has any suggestions, please say!
Fantastic article Monkey G.
I had the Jawbone Up for a while, but by the third time it broke down, I just asked for a refund. However, I have been using an app called sleep cycle, which allows you to tag the sleep data with up to 5 customised items, e.g. ate late, exercise etc. I wonder how easy it would be to design an open source experiment where you can get participants to tag their sleep data with pre-determined attributes before getting them to send in their results to analysed in an aggregate form. I wonder how you could remove the biases that would come out of such public data?
Anyway, just thinking out aloud.
RJ
Thanks for the comment, RJ. This is a great idea and brilliantly simple.
The issue of bias does matter, but I think there are ways around it. One approach is to concentrate on exploratory analysis (or epidemiological methods), that are primarily hypothesis-generating. This is one of the underlying strengths of large data sets – effects that are very difficult to see in individuals (because of all the other factors influencing sleep, performance etc.) can be seen in a large sample. For example, we may look at the variability of peoples’ sleep and note that people who eat late tend to get less sleep. There could be all sorts of reasons for this (because association is not the same as causation), but it creates a testable hypothesis.
Here’s the thing: If people are monitoring lots of different parameters and agree to be part of an experiment, we can ask them to eat at different times without necessarily telling them which particular consequence we are interested in. This means that we can run a proper randomized, controlled, experiment.
It’s not perfect – blinding people to the intervention won’t work, for example. However, we can minimize the biases present.
I quite like the idea of collecting lots of data routinely and using it to generate hypotheses that are then tested, and replicated, amongst a sample of users.
Actually, thinking about it, you could even go further. You could tell some people why you are doing it, and keep other people blind to the purpose. That would allow you to estimate the size of bias present, which would be pretty neat.
The underlying point is, as you say, having data entered in a consistent format so that you can collate it across people.
Interesting article and comments. Will check out this blog further. I am also thinking och taking stat class again. But maybe I should outsource my stat questions when needed.
Thanks!
This is great. Really fun read, and interesting data.
Three small comments:
1.) I spoke with Seth Roberts extensively about this before his passing, and he convinced me that a qualitative metric of how rested you feel with 3 significant digits would outperform trackers, and alleviate the ceiling effect. It’s lovely to collect data in an automated way like a jawbone would, but I am not sure keeping it charged it actually less effort than jotting down a three digit number would be. Switching to this metric might give you more reactive and richer data.
2.) I think it’s a mistake to assume that the effects of caffeine are monotonic. See gettingstronger.org for an excellent take on hormesis on non-monotonicity of most phenomena. It’s possible that smaller doses are better than zero or larger doses.
3.) You might also look at timing effects. For me, caffeine before and after noon are night and day different (literally I guess), and, say, 50mg caffeine at 9am and 4pm are totally different. Seth Roberts found this for Vitamin D as wel.
Thanks for a brilliantly useful and insightful comment, Brian.
I think I agree about self-reported sleep data. It is important to have some anchor point to avoid bias, but that’s manageable. Sometimes, it feels like we use tech for the sake of it when simpler solutions would be just as good.
Similarly, I agree on the issues of monotonicity and timing. Thanks for mentioning them. We take non-monotonic relationships for granted in drug pharmacokinetics, then forget them when talking about exercise or lifestyle interventions.
Anyway, great comments, and thanks for adding them.